
Peneliti menganalisis pola linguistik pengguna untuk memprediksi usia, jenis kelamin, dan tanggapan terhadap kuesioner kepribadian.
Di era media sosial, kehidupan batin seseorang semakin direkam melalui bahasa yang mereka gunakan online. Dengan pemikiran ini, sebuah kelompok interdisipliner dari University of Pennsylvania peneliti tertarik pada apakah analisis komputasi bahasa ini dapat memberikan sebanyak, atau lebih banyak, wawasan kepribadian mereka sebagai metode tradisional yang digunakan oleh psikolog, seperti survei yang dilaporkan sendiri dan kuesioner. .
Dalam sebuah studi baru-baru ini, yang diterbitkan dalam jurnal PLOS ONE, 75.000 orang secara sukarela mengisi kuesioner kepribadian umum melalui aplikasi dan membuat pembaruan status mereka tersedia untuk tujuan penelitian. Para peneliti kemudian mencari pola linguistik keseluruhan dalam bahasa sukarelawan.
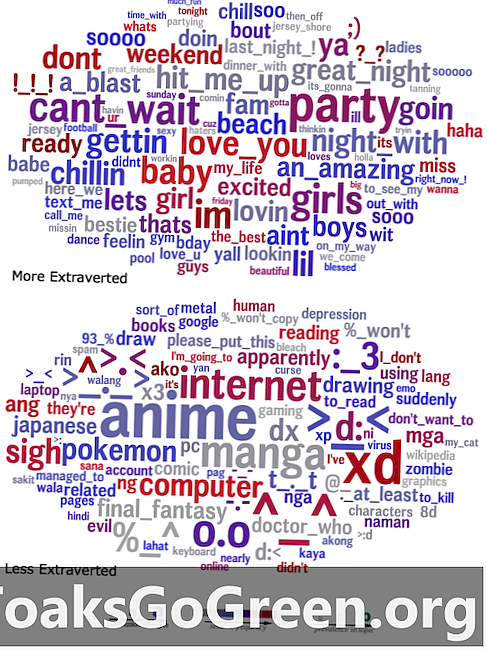
Kata cloud yang membandingkan bahasa yang extraverts (atas) dan introvert (bawah) digunakan dalam statusnya s.
Analisis mereka memungkinkan mereka untuk menghasilkan model komputer yang dapat memprediksi usia individu, jenis kelamin dan tanggapan mereka terhadap kuesioner kepribadian yang mereka ambil. Model prediksi ini ternyata sangat akurat. Sebagai contoh, para peneliti benar 92 persen saat memprediksi gender pengguna hanya berdasarkan bahasa pembaruan status mereka.
Keberhasilan pendekatan "terbuka" ini menunjukkan cara-cara baru untuk meneliti hubungan antara sifat-sifat kepribadian dan perilaku dan mengukur efektivitas intervensi psikologis.
Studi ini merupakan bagian dari Proyek Kesejahteraan Dunia, upaya interdisipliner dengan anggota Departemen Ilmu Komputer dan Informasi di Sekolah Teknik Penn dan Sains Terapan dan Departemen Psikologi dan Pusat Psikologi Positif di Sekolah Seni dan Sains.
Itu dipimpin oleh H. Andrew Schwartz, seorang rekan pascadoktoral dalam ilmu komputer dan informasi dan Pusat Psikologi Positif, dan termasuk mahasiswa pascasarjana Johannes Eichstaedt, rekan pascadoktoral Margaret Kern dan direktur Martin Seligman, semua Pusat Psikologi Positif, serta profesor Lyle Ungar dari Ilmu Komputer dan Informasi.

Kata cloud yang membandingkan bahasa yang digunakan oleh orang yang lebih muda (atas) dan lebih tua (bawah) dalam status mereka.
Tim Penn berkolaborasi dengan Michal Kosinski dan David Stillwell dari The Psychometrics Center di University of Cambridge, yang awalnya mengumpulkan data dari pengguna.
Penelitian para peneliti mengacu pada sejarah panjang mempelajari kata-kata yang digunakan orang sebagai cara memahami perasaan dan kondisi mental mereka, tetapi mengambil pendekatan "terbuka" daripada "tertutup" untuk menganalisis data pada intinya.
"Dalam pendekatan 'kosa kata tertutup'," kata Kern, "psikolog mungkin memilih daftar kata yang mereka pikir menandakan emosi positif, seperti 'puas,' 'antusias' atau 'luar biasa' dan kemudian melihat frekuensi penggunaan seseorang untuk kata-kata ini sebagai cara untuk mengukur seberapa bahagia orang itu. Namun, pendekatan kosa kata tertutup memiliki beberapa keterbatasan, termasuk bahwa mereka tidak selalu mengukur apa yang ingin mereka ukur. ”
"Misalnya," kata Ungar, "orang mungkin menemukan sektor energi menggunakan lebih banyak kata-kata emosi negatif, hanya karena mereka menggunakan kata 'kasar' lebih. Tapi ini menunjukkan perlunya menggunakan ekspresi multi-kata untuk memahami makna yang dimaksud. 'Minyak mentah' berbeda dari 'minyak mentah,' dan, juga, 'muak' berbeda dari sekadar menjadi 'sakit.'
Keterbatasan lain yang melekat pada pendekatan kosa kata tertutup adalah bahwa itu bergantung pada serangkaian kata yang telah ditentukan sebelumnya dan telah ditetapkan. Penelitian semacam itu mungkin dapat mengkonfirmasi bahwa orang yang depresi memang menggunakan kata-kata yang diharapkan (seperti "sedih") lebih sering tetapi tidak dapat menghasilkan wawasan baru (bahwa mereka berbicara lebih sedikit tentang olahraga atau kegiatan sosial daripada orang-orang yang bahagia, misalnya.)
Studi bahasa psikologis masa lalu harus mengandalkan pendekatan kosa kata tertutup karena ukuran sampel kecil mereka membuat pendekatan terbuka tidak praktis. Munculnya dataset bahasa masif yang diberikan oleh media sosial sekarang memungkinkan untuk analisis yang berbeda secara kualitatif.
"Kebanyakan kata jarang muncul - sampel tulisan apa pun, termasuk pembaruan status, hanya berisi sebagian kecil dari kosakata rata-rata," kata Schwartz. “Ini berarti bahwa, untuk semua kecuali kata-kata yang paling umum, Anda perlu menulis sampel dari banyak orang untuk membuat hubungan dengan ciri-ciri psikologis. Studi tradisional telah menemukan hubungan yang menarik dengan kategori kata yang telah dipilih sebelumnya seperti 'emosi positif' atau 'kata fungsi.' Namun, miliaran contoh kata yang tersedia di media sosial memungkinkan kita menemukan pola pada tingkat yang jauh lebih kaya. "
Sebaliknya, pendekatan kosakata terbuka menghasilkan kata dan frasa penting dari sampel itu sendiri. Dengan lebih dari 700 juta kata, frasa, dan topik yang dibor dari sampel status penelitian ini, ada cukup data untuk menggali ratusan kata dan frasa umum serta menemukan bahasa terbuka yang berkorelasi lebih bermakna dengan karakteristik khusus.
Ukuran data yang besar ini sangat penting untuk teknik spesifik yang digunakan tim, yang dikenal sebagai analisis bahasa diferensial, atau DLA. Para peneliti menggunakan DLA untuk mengisolasi kata-kata dan frasa yang berkerumun di sekitar berbagai karakteristik yang dilaporkan sendiri dalam kuesioner sukarelawan: usia, jenis kelamin, dan skor untuk ciri-ciri kepribadian "Lima Besar", yaitu extraversion, agreeableness, conscientiousness, neuroticism, dan openness. . Model Lima Besar dipilih karena merupakan cara umum dan dipelajari dengan baik untuk mengukur sifat-sifat kepribadian, tetapi metode para peneliti dapat diterapkan pada model yang mengukur karakteristik lain, termasuk depresi atau kebahagiaan.
Untuk memvisualisasikan hasil mereka, para peneliti membuat kata cloud yang meringkas bahasa yang secara statistik memprediksi sifat yang diberikan, dengan kekuatan korelasi kata dalam kelompok yang diberikan diwakili oleh ukurannya. Sebagai contoh, sebuah kata cloud yang menunjukkan bahasa yang digunakan oleh orang-orang luar secara jelas menampilkan kata-kata dan frasa seperti "pesta," "malam yang hebat" dan "pukul saya," sementara kata cloud untuk introvert menampilkan banyak referensi ke media dan emotikon Jepang.
"Mungkin tampak jelas bahwa orang yang super ekstran akan banyak berbicara tentang pesta," kata Eichstaedt, "tetapi jika disatukan, kata-kata ini memberikan jendela yang belum pernah terjadi sebelumnya ke dunia psikologis orang-orang dengan sifat yang diberikan. Banyak hal yang tampak jelas setelah fakta dan setiap item masuk akal, tetapi apakah Anda telah memikirkan semuanya, atau bahkan kebanyakan dari mereka? ”
“Ketika saya bertanya pada diri sendiri,” kata Seligman, “'Bagaimana rasanya menjadi ekstrovert?' 'Seperti apa rasanya menjadi gadis remaja?' 'Seperti apa menjadi skizofrenik atau neurotik?' Atau 'Seperti apa rasanya menjadi 70 tahun? 'Kata-kata ini awan lebih dekat ke inti masalah daripada semua kuesioner yang ada. "
Untuk menguji seberapa akurat mereka menangkap sifat-sifat orang melalui pendekatan kosakata terbuka mereka, para peneliti membagi sukarelawan menjadi dua kelompok dan melihat apakah model statistik yang diperoleh dari satu kelompok dapat digunakan untuk menyimpulkan sifat-sifat yang lain. Untuk tiga perempat dari sukarelawan, para peneliti menggunakan teknik pembelajaran mesin untuk membangun model kata-kata dan frasa yang memprediksi respons kuesioner. Mereka kemudian menggunakan model ini untuk memprediksi usia, jenis kelamin dan kepribadian untuk kuartal yang tersisa berdasarkan posting mereka.
"Model itu 92 persen akurat dalam memprediksi jenis kelamin sukarelawan dari penggunaan bahasa mereka," kata Schwartz, "dan kami bisa memprediksi usia seseorang dalam tiga tahun lebih dari separuh waktu. "Prediksi kepribadian kita secara inheren kurang akurat tetapi hampir sama baiknya dengan menggunakan hasil kuesioner seseorang dari satu hari untuk memprediksi jawaban mereka terhadap kuesioner yang sama pada hari lain."
Dengan pendekatan kosakata terbuka terbukti sama atau lebih prediktif daripada pendekatan tertutup, para peneliti menggunakan kata cloud untuk menghasilkan wawasan baru ke dalam hubungan antara kata dan sifat. Misalnya, peserta yang mendapat skor rendah pada skala neurotik (yaitu, mereka yang memiliki stabilitas paling emosional) menggunakan lebih banyak kata yang merujuk pada kegiatan sosial aktif, seperti "papan luncur salju," "rapat" atau "bola basket."
“Ini tidak menjamin bahwa melakukan olahraga akan membuat Anda kurang neurotik; bisa jadi neurotisme menyebabkan orang menghindari olahraga, ”kata Ungar. "Tapi itu menunjukkan bahwa kita harus mengeksplorasi kemungkinan bahwa orang-orang neurotik akan menjadi lebih stabil secara emosional jika mereka bermain lebih banyak olahraga."
Dengan membangun model prediksi kepribadian berdasarkan bahasa media sosial, para peneliti sekarang dapat lebih mudah mendekati pertanyaan-pertanyaan seperti itu. Alih-alih meminta jutaan orang untuk mengisi survei, studi selanjutnya dapat dilakukan dengan meminta sukarelawan menyerahkan atau memberi makan mereka untuk studi anonim.
"Para peneliti telah mempelajari ciri-ciri kepribadian ini selama beberapa dekade secara teoritis," kata Eichstaedt, "tetapi sekarang mereka memiliki jendela sederhana tentang bagaimana mereka membentuk kehidupan modern di zaman."
Dukungan untuk penelitian ini diberikan oleh Pioneer Portofolio Robert Wood Johnson Foundation.
Programmer riset Lukasz Dziurzynski dan asisten peneliti Stephanie M. Ramones, keduanya Psikologi, dan mahasiswa pascasarjana Megha Agrawal dan Achal Shah, keduanya dari Ilmu Komputer dan Informasi, juga berkontribusi dalam penelitian ini.
Melalui Universitas Pennsylvania